Apache Spark (스파크)란?
- 대규모 데이터 처리를 위한 오픈 소스 통합 컴퓨팅 엔진
- Hadoop의 속도적 한계를 극복하기 위하여 2009년 등장
- 분산 데이터 처리 작업을 빠르고 효율적으로 수행할 수 있는 엔진 제공
- 빅데이터 어플리케이션 개발에 필요한 통합 플랫폼을 제공하는 것이 핵심 목표 (스파크 하나로 모든 처리를 마무리)
스파크 코어 및 에코시스템

- 스파크가 제공하는 모든 기능들은 스파크 코어 위에 구축되어 있음
- 필수 I/O 기능을 담당함
- 스파크 클러스터의 역할을 프로그래밍하고 관찰, 인메모리 연산 기능을 제공하여 빠른 속도를 제공
인메모리 연산:
- 데이터를 하드디스크에 저장하고 관리하는 것이 아닌, 전체 데이터를 메모리에 적재하여 사용
- 장점: 고속처리 가능 (네트워크나 디스크보다 10~100배의 속도)
- 단점: 저장공간 한정적, 프로세스가 갑자기 종료될 시 데이터가 유실될 수 있음
에코시스템
1) Spark SQL
정형 데이터 처리를 위한 스파크 모듈
하이브 메타스토어 (하이브에서 생성한 테이블 정보를 저장하는 공간)를 사용하여 하이브와 연동
2) Spark Streaming
실시간으로 들어오는 데이터를 처리하기 위한 모듈
3) MLlib
Machine Learining Library의 약자이며, 스파크 기반에서 머신 러닝(Machine Learning)을 쉽고 확장성 있게 적용
4) GraphX
대용량 데이터의 분산 및 병렬 그래프 처리를 지원
5) SparkR
Spark에서 R을 실행하는 데 쓰는 툴
스파크의 데이터 구조
1. RDD(Resilient Distributed Dataset)

스파크의 가장 기본적인 데이터 단위
특징
1) 데이터 추상화
- 데이터는 클러스터에 흩어져 있지만, 하나의 파일인 것처럼 활용이 가능
2) 탄력적 & 불변성
- 불변 (Read-Only)의 특징을 가지고 있음
- 특정 동작을 수행하기 위해선 기존 RDD를 변형한 새로운 RDD 생성이 필요

- 변환을 거칠 때마다 연산 기록이 남음
- RDD의 변환 과정은 비순환 그래프 (Acyclic Graph)이기 때문에, 문제가 생길 경우 쉽게 이전 RDD로 돌아갈 수 있음
3) 타입 세이프 (Type-Safe)

- 컴파일 시 각 Type를 판별 가능 -> 개발자 친화적
4) 정형, 비정형 데이터를 모두 담을 수 있음

5) Lazy Evaluation
스파크는 Lazy Evaluation을 통해 연산 실행 계획을 최적화 가능
- 사용자가 입력한 연산들을 즉시 수행하지 않고, 메타데이터에 연산이 요청되었다는 사실만 기록함
- 이를 통해 연산의 최적 수행 방법을 미리 수립
- Action 함수가 호출되기 전까진 실제 데이터 로딩이나 연산이 이뤄지지 않음
- Transformation: 기존의 RDD에서 새로운 RDD를 생성하는 기능
- Action: 실제 연산 작업을 진행 (함수 호출 시, executor가 driver에 전달한 task 수행)

2. DataFrame
- 행과 열로 구성된 데이터 분산 컬렉션

- Pandas의 DataFrame과 비슷한 개념
- RDD의 성능적 이슈를 해결하기 위해 등장
- 메모리나 디스크에 저장 공간이 충분하지 않으면 제대로 동작 X
- 스키마 (DB 구조) 개념이 별도로 존재하지 않음
- RDD는 직렬화 (데이터를 배포하거나 디스크에 데이터를 기록할 때마다 Java의 직렬화 사용)와 Garbage Collection (사용되지 않는 객체를 자동으로 메모리에서 해제)을 기본적으로 사용하는 데, 이는 메모리 오버헤드를 증가시킴
DataFrame의 특징
- 구조화된 데이터 구조: SparkSQL 등을 통해 구조화된 데이터의 쿼리를 처리 가능
- GC (Garbage Collection) 오버헤드 감소: RDD는 데이터를 메모리에 저장하지만, DataFrame은 데이터를 Off-heap(GC의 영향을 받지 않는, 디스크가 아닌 RAM 영역) 영역에 저장함. 이를 통해 GC의 오버헤드를 감소
- Off-heap 메모리를 사용한 직렬화를 통해 오버헤드 감소
- 탄력성 & 확장성: CSV, 카산드라 등 다양한 형태의 데이터를 직접 지원
3. Dataset
- 구조적 API의 기본 데이터 타입
- DataFrame은 Row 타입의 Dataset
- 자바 가상 머신을 사용하는 스칼라와 자바에서만 사용 가능
사용할 시기:
- DataFrame 기능만으로는 수행할 연산을 표현할 수 없는 경우
- 성능 저하를 감수하더라도 타입 안정성(type-safe)을 가진 데이터 타입을 사용하고 싶은 경우
스파크 구성 및 실행 과정
1. 스파크 어플리케이션 (Spark Application)

Driver Process와 Executor Process로 구성
Driver: 한 개의 노드에서 실행되며, 스파크 전체의 main함수 실행
- Application 내 정보 관리, Executor 실행 및 분석, 배포 등의 역할 수행
- 사용자가 구성한 Job을 task로 변환하며, Executor로 전달
스파크 Job의 구조
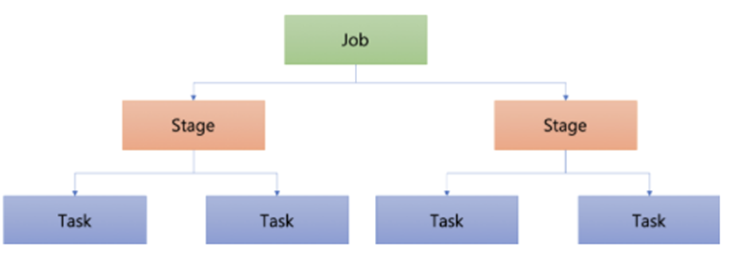
- Job: 스파크 앱에 제출된 작업
- Stage: 단위에 따라 구분하는 작업. Job을 여러 개의 Stage로 나눌 수 있음
- Task: Executor에서 실행되는 실제 작업의 단위
- Executor: 다수의 worker 노드에서 실행되는 process
- Spark Driver가 할당한 task를 수행하여 결과를 반환
- 블록매니저를 통해 RDD를 저장
- 1개의 스파크 어플리케이션에는 1개의 Spark Driver와 N개의 Executor가 존재함
2. 클러스터 매니저 (Cluster Manager)
- 스파크 어플리케이션의 리소스를 효율적으로 분배하는 역할
- Executor에 task를 할당하고 관리하기 위해 클러스트 매니저가 필요
- 사용 가능한 클러스터 매니저: Spark StandAlone, Yarn, Mesos, Kubernetes
- Spark StandAlone은 클러스터가 아닌 단일 컴퓨터에서 스파크 전체를 동작시키는 방식
'Data Engineering' 카테고리의 다른 글
| 데이터 거버넌스(Data Governance) (0) | 2025.05.01 |
|---|---|
| 데이터 파이프라인(Data Pipeline) (0) | 2025.04.01 |
| 데이터 레이크(Data Lake) (0) | 2025.03.02 |
| Apache Spark 로컬 환경 구성 (0) | 2024.03.26 |
| Apache Hive 정리 (0) | 2024.01.14 |


