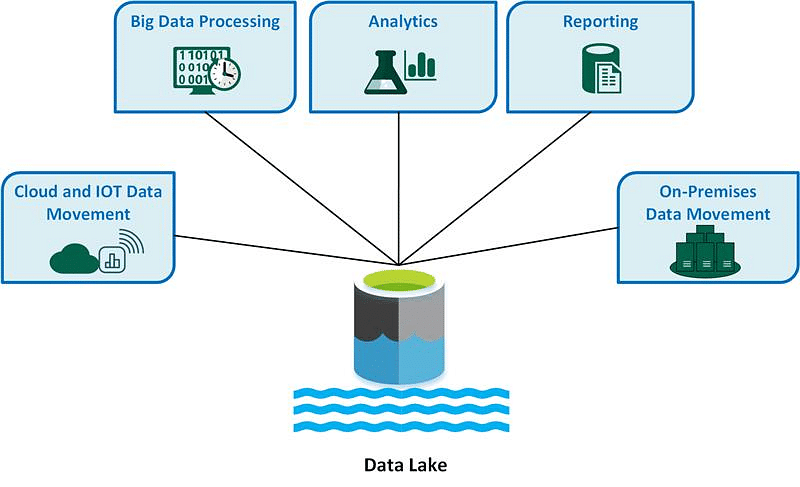
정형, 반정형, 비정형 데이터를 가리지 않고 모든 종류의 데이터를 원래 형식 그대로 저장하는 중앙 집중식 저장소
전통적인 데이터 웨어하우스(Data Warehouse)가 정형화된 데이터만 구조화해서 저장하는 것과 달리, 데이터 레이크는 날 것의 데이터를 그대로 저장해서 나중에 필요할 때 원하는 방식으로 가공해서 사용할 수 있다는 점이 가장 큰 특징입니다.
-> 즉, 데이터의 호수 (원하는 대로 활용할 수 있도록 일단 모든 데이터를 다 모아놓는 곳)!
데이터 레이크와 데이터 웨어하우스의 차이점
둘 다 데이터를 저장하는 공간이지만, 목적과 방식에서 큰 차이가 있습니다.
1. 데이터 유형
- 데이터 레이크: 정형, 반정형(로그 파일, XML), 비정형(텍스트, 이미지, 비디오) 등 모든 종류의 데이터를 원본 그대로 저장합니다. 데이터를 저장하기 전에 미리 구조를 정의할 필요가 없습니다.
- 데이터 웨어하우스: 관계형 데이터베이스처럼 미리 정해진 스키마(구조)에 맞춰 정형화된 데이터만 저장합니다. 분석을 위해 데이터를 정제하고 변환하는 과정(ETL)을 거쳐야 합니다.
2. 저장 비용 및 확장성
- 데이터 레이크: 저렴한 저장 공간(예: 클라우드 기반 스토리지)을 사용하고, 엄청난 양의 데이터를 무한정 확장하여 저장할 수 있습니다.
- 데이터 웨어하우스: 고성능 데이터베이스를 사용하기 때문에 상대적으로 비용이 높고, 확장성에 제약이 있을 수 있습니다.
3. 사용 목적
- 데이터 레이크: 주로 탐색적 분석, 머신러닝, 실시간 분석 등 다양한 목적으로 데이터를 활용할 수 있습니다. 아직 용도가 불분명한 데이터도 일단 저장해두었다가 나중에 새로운 가치를 찾아낼 때 유용합니다.
- 데이터 웨어하우스: 주로 비즈니스 인텔리전스(BI), 보고서 생성, 정형화된 쿼리 분석 등 미리 정의된 목적의 분석에 사용됩니다.
데이터 레이크의 장단점
장점
- 유연성: 다양한 형식의 데이터를 저장하고, 필요에 따라 다양한 방식으로 분석할 수 있어서 유연성이 높습니다.
- 비용 효율성: 저렴한 저장 공간을 활용하여 대량의 데이터를 효율적으로 저장할 수 있습니다.
- 빠른 데이터 수집: 데이터를 사전 처리할 필요 없이 원본 그대로 저장하기 때문에 데이터 수집 속도가 빠릅니다. 새로운 데이터 소스가 생겨도 쉽게 통합할 수 있습니다.
- 미래 지향적: 아직 분석 목적이 명확하지 않은 데이터도 일단 저장해두고, 나중에 새로운 기술이나 분석 기법이 발전하면 활용할 수 있습니다.
단점
- 데이터 거버넌스 및 관리의 어려움: 워낙 다양한 데이터를 원본 그대로 저장하다 보니, 데이터의 품질 관리나 보안, 접근 권한 설정 등 데이터 거버넌스가 중요해집니다.
- 데이터 품질 문제: 정제되지 않은 데이터가 많기 때문에 분석 전에 추가적인 데이터 정제 작업이 필요할 수 있으며, 잘못된 데이터로 인해 분석 결과가 왜곡될 위험도 있습니다.
- 기술적 복잡성: 데이터 레이크를 구축하고 운영하려면 하둡(Hadoop), 스파크(Spark) 등 빅데이터 관련 기술에 대한 이해와 전문성이 필요합니다.
'Data Engineering' 카테고리의 다른 글
| 데이터 거버넌스(Data Governance) (0) | 2025.05.01 |
|---|---|
| 데이터 파이프라인(Data Pipeline) (0) | 2025.04.01 |
| Apache Spark 로컬 환경 구성 (0) | 2024.03.26 |
| Apache Spark 기본 정리 (0) | 2024.03.15 |
| Apache Hive 정리 (0) | 2024.01.14 |

